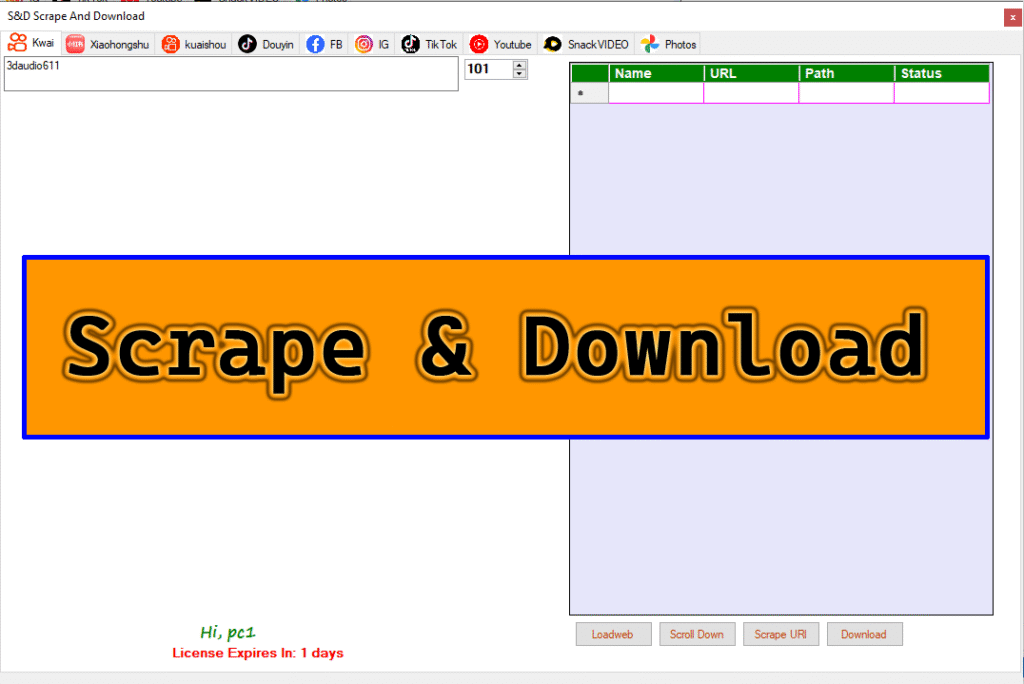
Overview: Focuse Download on facebook ,
- Photos
- Reels
- Videos
“Scrape and Download” is a versatile tool designed to extract and download media content (photos, reels, videos) from Facebook. The program provides an intuitive interface with features like URL navigation, scraping, storing data in a structured format, and downloading media files. It is ideal for users who want to save and organize content from Facebook efficiently.

Key Features:
- Download Media Types:
- Photos
- Reels
- Videos
- Simple URL Input Box:
- A textbox where users can input the Facebook URL of the desired content.
- Supports Facebook platform URLs.
- Numeric Up/Down Control:
- Allows users to set a limit on the number of items (e.g., photos, videos) to scrape.
- Ensures controlled and manageable scraping operations.
- WebView Browser Integration:
- Built-in WebView that acts as a browser to open and navigate Facebook.
- Provides a seamless browsing experience within the application.
- DataGridView for Data Storage:
- Displays scraped data in a tabular format with the following columns:
- UserID : Unique identifier of the user who posted the content.
- Title : Title or description of the content.
- URL : Direct link to the media file.
- Path : Local file path where the downloaded content is stored.
- Status : Indicates whether the item has been successfully scraped or downloaded (e.g., “Pending,” “Scraped,” “Downloaded”).
- Displays scraped data in a tabular format with the following columns:
- Control Buttons:
- Start Load Web : Opens the specified Facebook URL in the WebView browser.
- Start Scrape : Initiates the scraping process to extract media data from the loaded page.
- Start Download : Opens a dialog box to select the download location and starts downloading the scraped media files.
Detailed Functionality:
1. Download Media Types
- The program supports downloading three types of media: photos, reels, and videos.
- Users can choose which type of content they want to scrape and download by selecting the appropriate option.
2. URL Navigation Textbox
- A simple textbox allows users to paste the URL of the Facebook page or post containing the desired media.
- Example:
https://www.facebook.com/user/posts/123456789 - Validation ensures that only valid Facebook URLs are accepted.
3. Numeric Up/Down Limit Amount
- A numeric control lets users specify the maximum number of items to scrape.
- For example, if the user sets the limit to 10, the program will scrape only the first 10 photos, reels, or videos it finds.
4. WebView Browser
- The WebView component acts as an embedded browser, allowing users to load and interact with Facebook pages directly within the application.
- This eliminates the need for an external browser and streamlines the workflow.
5. DataGridView for Storing Data
- The DataGridView displays all scraped data in a structured table format.
- Columns:
- UserID : Extracts the unique identifier of the user who posted the content.
- Title : Captures the title or description of the media file.
- URL : Stores the direct link to the media file.
- Path : Shows the local file path where the media is saved after downloading.
- Status : Tracks the progress of each item (e.g., “Pending,” “Scraped,” “Downloaded”).
- Users can sort, filter, and review the data easily.
6. Control Buttons
- Start Load Web:
- When clicked, this button loads the URL entered in the textbox into the WebView browser.
- Ensures the correct page is displayed before scraping begins.
- Start Scrape:
- Initiates the scraping process.
- Extracts relevant data (UserID, Title, URL) from the loaded Facebook page.
- Populates the DataGridView with the scraped information.
- Start Download:
- Opens a dialog box for the user to select the download location.
- Downloads the media files (photos, reels, videos) from the URLs listed in the DataGridView.
- Updates the “Path” and “Status” columns in the DataGridView accordingly.
User Workflow:
- Step 1: Enter URL
- Paste the Facebook URL of the desired content into the textbox.
- Example:
https://www.facebook.com/user/posts/123456789
- Step 2: Set Limit
- Use the numeric up/down control to specify the maximum number of items to scrape.
- Step 3: Load Web Page
- Click the “Start Load Web” button to open the URL in the WebView browser.
- Step 4: Scrape Data
- Click the “Start Scrape” button to extract media data from the loaded page.
- The scraped data will appear in the DataGridView.
- Step 5: Download Media
- Click the “Start Download” button to open a dialog box for selecting the download location.
- The program will download the media files and update the DataGridView with the file paths and statuses.
Technical Details:
- Programming Language: C# (or Python, depending on your preference)
- Libraries/Frameworks:
- VB.net
- C#: WinForms or WPF for the GUI, WebView2 for the browser component, and HttpClient for web scraping.
- Python: Tkinter or PyQt for the GUI, Selenium or BeautifulSoup for web scraping, and requests for downloading files.
- Data Storage: Temporary storage in memory (DataGridView). Optionally, export scraped data to CSV or JSON for backup.
Future Enhancements:
- Multi-Platform Support:
- Extend support to other social media platforms like Instagram, Twitter, etc.
- Batch Processing:
- Allow users to scrape and download multiple URLs at once.
- Advanced Filtering:
- Add filters to scrape content based on date, user, or media type.
- Cloud Integration:
- Enable direct uploads to cloud storage services like Google Drive or Dropbox.
- Error Handling:
- Implement robust error handling for invalid URLs, network issues, or restricted content.
- Step 1: Enter URL